

Jetzt geht es langsam in die letzte Runde. Ich habe bisher mit den Projektbereichen U, D und S geredet und alle sprachen von der „wundersamen Geheimkiste der Mathematik und Informatik“. Ich bin fast ein bisschen aufgeregt. Was wohl die Kolleginnen und Kollegen aus dem Projektbereich P dazu zu sagen haben? Und welche Rolle spielt der Projektbereich P überhaupt innerhalb des SFBs 1232? Denn auf den ersten Blick haben Informatiker und Mathematiker ja gar nichts mit der Entdeckung von neuen Werkstoffen zu tun… oder?
Als ich in Rolf Drechslers Büro ankomme – etwas außer Atem, da es im 4. Stock eines Hochhauses liegt und ich den Fahrstuhl verpasst habe – stelle ich fest, der Leiter der beiden Teilprojekte P01 und P02 und sein wissenschaftlicher Mitarbeiter Sebastian Huhn, den ich schon aus „Schule in Farbigen Zuständen“ kenne, sehen auf den ersten Blick total normal aus und haben nichts gemeinsam mit meiner Assoziation von grübelnden Wissenschaftlern, die vor riesigen Computerbildschirmen sitzen und irgendwelche Berechnungen anstellen. Da ging wohl meine Phantasie ein bisschen mit mir durch.
Jedenfalls kann ich es kaum erwarten, die beiden mit meinen Fragen zu bombardieren. Immerhin grenzt für mich, die ich nie viele Berührungspunkte mit Informatik oder der höheren Mathematik hatte, die Arbeit in den beiden Teilprojekten P01 und P02 fast schon an Science-Fiction. Die Wissenschaftler sammeln die Daten, die ihnen die anderen Projektbereiche zuschicken und sind in der Lage daraus „Kochrezepte“ für neue Werkstoffe zu entwickeln. Wie funktioniert das, frage ich mich.
Und meine Neugier wird auch schnell gestillt. Das, was Herr Drechsler und sein Team tun, ist längst kein Hexenwerk, sondern ihr ganz normaler wissenschaftlicher Alltag, erklärt er mir. Wie schon erwähnt, beschäftigt sich vor allem das Teilprojekt P01 (Projektbearbeitende: Sebastian Huhn und Mareike Picklum) zunächst mit dem Zusammentragen der Daten aus den anderen Projektbereichen. Dabei werden die Daten aus den Projektbereichen U und D, die sich mit den Mikroproben beschäftigen, durch Daten aus dem Projektbereich S unterstützt, der die Makroebene bearbeitet. Von den Makroproben kann man nämlich mit normierten Verfahren die Werkstoffeigenschaften ermitteln, beispielweise die Dichte eines Stoffes oder auch die Zugfestigkeit. Im Gegensatz dazu ist die Ermittlung der Werkstoffeigenschaften bei den Mikroproben nicht direkt möglich; die Größe der Proben ist dafür einfach nicht ausreichend.

Deshalb verwenden die Wissenschaftler die Ebene der Deskriptoren, welche beschreibende Werte liefern (Was sind eigentlich Deskriptoren?). Diese Daten werden sowohl auf der Mikro- als auch Makroebene ermittelt, natürlich an vergleichbaren Proben. Hieraus kann dann die notwendige Erfahrung gewonnen werden, wie man von den Mikrodeskriptoren auf die Makrodeskriptoren hochrechnen kann. Weiß man nun auch noch etwas über den Zusammenhang zwischen den Makrodeskriptoren und Werkstoffeigenschaften, die sich ja an den Makroproben problemlos ermitteln lassen, kann man durch zweifaches Hochrechnen direkt von den Mikrodeskriptoren auf die (Mikro-)Werkstoffeigenschaften schließen – damit tricksen die Wissenschaftler quasi die Physik aus, sagen sie etwas schmunzelnd.
Um dieses Hochrechnen zu erlernen, werden sogenannte Stützstellen verwendet. Bei der Hochskalierung der Mikrowelt auf die Makrowelt fungieren sie als Orientierungswert.
Irgendwann soll die benötigte Anzahl an Stützstellen jedoch stark reduziert werden und man möchte fähig sein, nur aus Daten der Mikrowelt Vorhersagen über vielversprechende Legierungszusammensetzungen oder Prozesse machen zu können.
Denn genau das bedeutet Prädiktorfunktion im Endeffekt: Vorhersagen.
Und diese Vorhersagen müssen natürlich reproduzierbar sein, weshalb möglichst viele Daten gesammelt und Experimente wiederholt werden müssen. Durch dieses „Refinement“ wird der Datensatz immer weiter verbessert, sodass die Vorhersagen immer genauer werden.
Mir ist immer noch nicht klar, wie aus diesen ganzen Daten eine Vorhersage über ein noch unbekanntes Material getroffen werden kann. Doch Sebastian erklärt mir, das wäre „ganz einfach“. Und die Idee dahinter ist tatsächlich gar nicht so schwer zu verstehen. Die Basis für die Vorhersage ist das sogenannte „initiale Training“. Dieses besteht aus Deskriptoren aus der Mikro- und Makroebene und zusätzlich bei den Makroproben ermittelten Daten über die Werkstoffeigenschaften. Aus diesen Daten lässt sich sowas wie eine Gerade zeichnen, ähnlich wie bei der Linearen Regression – und wem das, so wir mir zunächst, nichts mehr sagt, die Aufgabe im Mathebuch der 10. Klasse lautete in etwa so „Du hast zwei Punkte mit den Koordinaten X und Y. Zeichne einen Grafen und bestimme die Geradengleichung in der Form m*x+b.“ Also eigentlich total einfach.
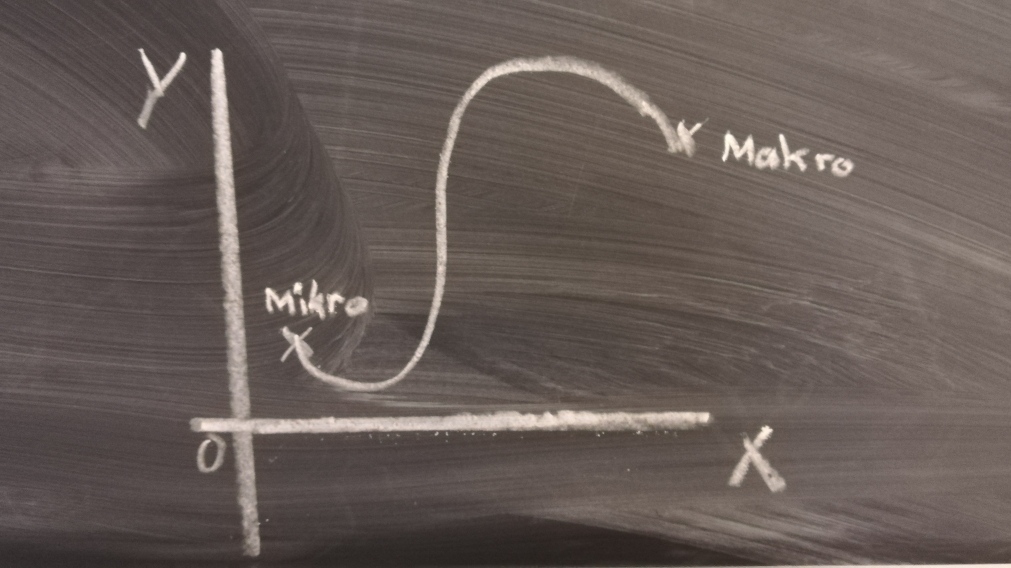
Genauso, bloß natürlich in einer anderen Dimensionalität verhält es sich auch bei den Vorhersagen im Teilprojekt P01. Die Daten der Mikroproben sind die eine Koordinate und die Daten der Makroproben die andere. Dadurch lässt sich eine Gerade zeichnen und alle Punkte dazwischen ermitteln. Jedoch verläuft zwischen diesen Punkten meist nicht einfach eine gerade Linie, sondern in der Realität liegt oftmals ein wilder Kurvenverlauf dazwischen, weshalb es eben so wichtig ist viele Versuche durchzuführen, damit die Prädiktion am Ende stabiler ist.
Im nächsten Beitrag wird dann auch noch das Geheimnis der Versuchspläne gelüftet.
Emilia Kurilov ist von Oktober 2017 bis Dezember 2019 studentische Mitarbeiterin im TP Öffentlichkeitsarbeit. Sie studiert Medien-, Kommunikations- und Wirtschaftswissenschaft an der Uni Bremen.
Bildquellen
- Mikroproben: SFB 1232
- Graph Projektbereich P: Emilia Kurilov
- Sebastian Huhn und Rolf Drechsler lüften Geheimnisse der Informatik: SFB 1232 / Claudia Sobich